LongCat-2.0
1.6T open-source MoE for agentic coding — native 1M context, trained on 50K domestic compute (Released: June 30, 2026)
Overview
LongCat-2.0 is Meituan LongCat's next-generation trillion-parameter open-source model, purpose-built for agentic coding — code understanding, generation, and execution in real-world agent workflows. With 1.6T total parameters and dynamic activation of 33B–56B (averaging ~48B) per token, it is the industry's first trillion-parameter model to complete full training and inference on a 50,000-card domestic compute cluster.
Pretrained from scratch on 30T+ tokens spanning Chinese, English, multilingual, and code data, LongCat-2.0 natively supports 1 million token context. A preview version has been available on OpenRouter and longcat.ai, ranking among the top three models globally by call volume on OpenRouter.
- longcat.ai — online experience
- OpenRouter — global API access
- LongCat API platform — longcat.chat/platform/usage
Model weights and self-hosted deployment guides will be linked here when officially published on Hugging Face / GitHub.
Architecture
LongCat Sparse Attention (LSA) — 1M Context
Traditional models begin to "forget" content beyond ~100K tokens. LSA intelligently selects key information instead of attending to every token, reducing computation from quadratic to linear complexity. This enables precise information retrieval and understanding across 1 million tokens — letting agents see an entire codebase at once.
Zero-Computation Experts + ScMoE
Code tasks vary enormously in complexity — naming a variable vs. deriving a recursive algorithm require vastly different compute. Zero-computation experts enable token-level dynamic activation: simple tokens consume no compute, while complex tokens automatically receive more resources (33B–56B range).
MOPD Multi-Expert Fusion
LongCat-2.0 fuses three expert groups through MOPD (Multi-Teacher On-Policy Distill). Training starts from a LongCat SFT checkpoint, branches into specialized experts, and distills their capabilities into one unified model on domestic accelerator clusters:
- Agent Experts: Tool use, API parsing, and self-correction
- Reasoning Experts: Multi-hop reasoning, STEM reasoning, and adaptive computation
- Interaction Experts: Instruction following, human alignment, and hallucination suppression
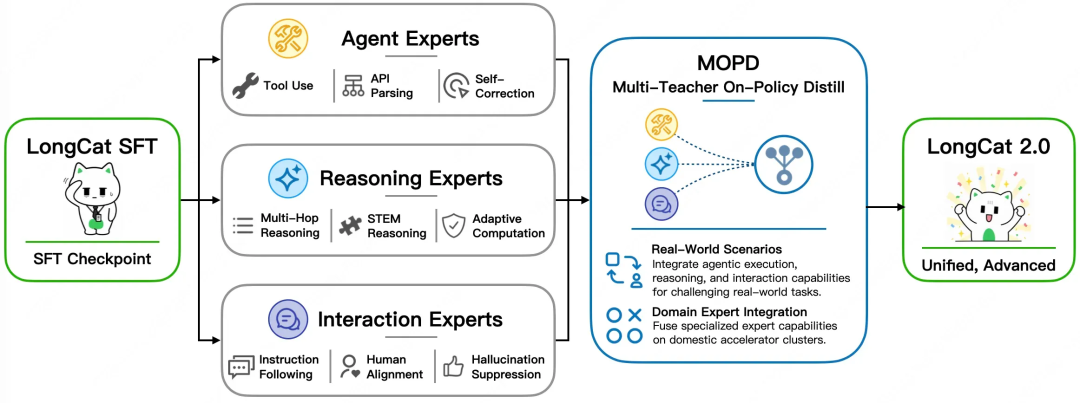
At inference time, a gating network dynamically routes each task to the most capable experts, rather than simply merging parameters.
Benchmark Performance
| Benchmark | LongCat-2.0 | Focus |
|---|---|---|
| SWE-bench Pro | 59.5 | Deep software engineering (leads Gemini 3.1 Pro 54.2, GPT-5.5 58.6, Claude Opus 4.6 57.3) |
| SWE-bench Multilingual | 77.3 | Multilingual coding (on par with Claude Opus 4.6 77.8) |
| Terminal-Bench 2.1 | 70.8 | Real terminal command interaction |
| RWSearch | 78.8 | Search agent tasks |
| FORTE | 73.2 | Productivity scenarios |
| BrowseComp | 79.9 | Complex browsing and retrieval |
Real-World Use Cases
- Agent building: End-to-end AI SQL Agent — natural language queries, step planning, and business insights
- Codebase migration: Analyze legacy code, map to new SDK APIs, refactor with full feature parity and compile-first-pass
- Full app development: From one-sentence idea to runnable product with architecture, logic, and UI
- 3D interactive demos: Single-file Three.js experiences from natural language descriptions
- AI content pipelines: Multi-agent novel factory with million-token setting consistency
Training on Domestic Compute
LongCat's exploration of domestic compute began in 2023. Over three years, the team scaled from thousands to 50,000 cards, solving operator adaptation, communication optimization, and distributed stability challenges.
- Stability: HCCL exception handling, elastic scaling, auto fault recovery — 70%+ reduction in monthly daily fault rate
- Correctness: Deterministic operators, bitwise consistency verification, parameter detection
- Efficiency: Pipeline scheduling, memory optimization, operator-level core control — 1.5× MFU improvement
- Throughput: Steady-state daily throughput exceeding 1T tokens/day