LongCat-2.0 Officially Released
A trillion-parameter open-source model for agentic coding — trained end-to-end on 50K domestic compute.
Today, Meituan officially releases and open-sources LongCat-2.0, the next-generation trillion-parameter large language model. As the industry's first model of this scale to complete full training and inference on a 50,000-card domestic compute cluster (1.6T total parameters, ~48B average activation, dynamic range 33B–56B), LongCat-2.0 was pretrained from scratch with native support for 1M ultra-long context.
Its architecture was designed from the ground up around one core goal: enabling models to complete code understanding, generation, and execution more efficiently and reliably in real agentic coding tasks.
Before the official release, the LongCat-2.0 preview has been available globally via OpenRouter and longcat.ai — ranking among the top three models globally by call volume on OpenRouter, and becoming one of the most popular models among agent developers worldwide (widely used in Hermes, Claude Code, OpenClaw, and similar agent frameworks).
Training at Scale on Domestic Compute
LongCat's exploration of domestic compute began in 2023. Over three years, the team scaled from thousands of cards to 50,000, systematically solving operator adaptation, communication optimization, and distributed stability challenges.
LongCat-2.0's pretraining corpus exceeds 30T tokens, covering Chinese, English, multilingual, and code data. Facing hardware failures, communication anomalies, memory pressure, and numerical fluctuations at 10K-card scale, the team addressed training challenges across three dimensions:
Stability
- HCCL exception handling, elastic card scaling, and automatic fault recovery
- Monthly daily fault rate reduced by 70%+
Correctness
- Self-designed deterministic operators and bitwise consistency verification
- Parameter detection to ensure training result reliability
- Enhanced precision for key modules and optimized Reduce logic
Efficiency
- Pipeline scheduling, memory optimization, and operator-level core control
- Training MFU improved by 1.5×
- Steady-state daily throughput exceeding 1T tokens/day
Inference Optimization
LongCat-2.0's inference stack co-optimizes model, operators, and framework:
- Large-scale expert parallelism aggregates memory bandwidth for low-latency trillion-parameter MoE decoding
- Zero-computation expert integration into expert-parallel communication — tokens routed to zero experts truly avoid unnecessary transmission and computation
- Core operator scheduling for communication, Attention, and GEMM, combined with prefetch and early dispatch framework mechanisms
Architecture for Agentic Coding
1M Context — Agents See the Whole Project
Traditional models begin to "forget" earlier content beyond ~100K tokens. LongCat-2.0 adopts LongCat Sparse Attention (LSA): instead of attending to every token sequentially, it intelligently selects key information, reducing computation from quadratic to linear complexity. This enables precise information localization across 1 million tokens.
Zero-Computation Experts + ScMoE
Code tasks have vastly different token complexity — defining a variable name vs. deriving a recursive algorithm require completely different compute. LongCat-2.0 achieves token-level dynamic activation (33B–56B): simple tokens consume no compute, complex tokens automatically receive more resources.
MOPD — One Model, Multiple Strengths
Through MOPD (Multi-Teacher On-Policy Distill), LongCat-2.0 fuses three specialized expert groups distilled from a LongCat SFT checkpoint:
- Agent Experts: Tool use, API parsing, and self-correction
- Reasoning Experts: Multi-hop reasoning, STEM reasoning, and adaptive computation
- Interaction Experts: Instruction following, human alignment, and hallucination suppression
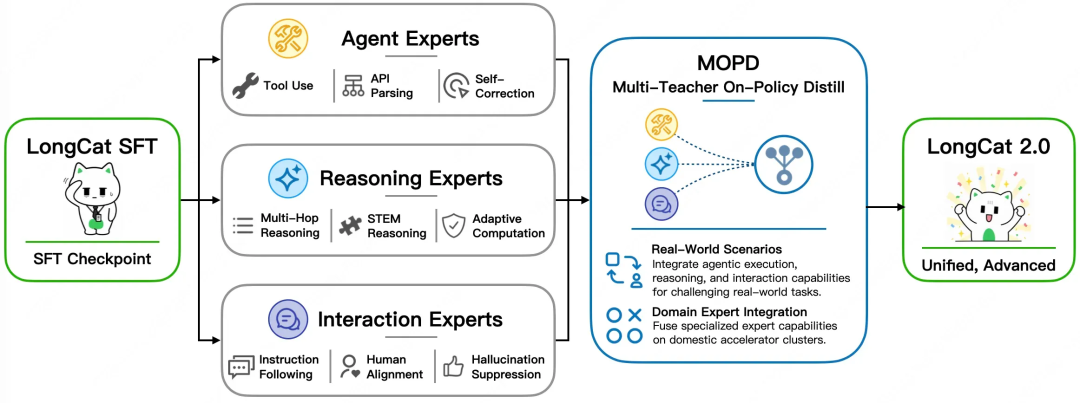
At inference time, a gating network dynamically dispatches the most capable experts based on task type, rather than simply merging parameters.
Benchmark Results
Comprehensive evaluation shows LongCat-2.0 delivers outstanding performance in both code and general agent scenarios:
| Benchmark | Score | Comparison |
|---|---|---|
| SWE-bench Pro | 59.5 | Leads Gemini 3.1 Pro (54.2), GPT-5.5 (58.6), Claude Opus 4.6 (57.3) |
| SWE-bench Multilingual | 77.3 | On par with Claude Opus 4.6 (77.8) |
| Terminal-Bench 2.1 | 70.8 | Real terminal command interaction |
| RWSearch | 78.8 | Search agent evaluation |
| FORTE | 73.2 | Productivity scenarios |
| BrowseComp | 79.9 | Complex browsing tasks |
Real-World Applications
During internal testing, LongCat-2.0 demonstrated reliable performance across diverse real-world workflows:
Agent Building — End-to-End Delivery
An AI SQL Agent built with LongCat-2.0 lets business users query data in natural language. The model handles the full loop: understanding intent, planning query steps, and converting results into clear business insights.
Codebase Migration
Given a legacy plugin codebase and new SDK documentation, LongCat-2.0 analyzes the overall architecture, maps core logic, and refactors the entire plugin to the new API — preserving all functionality, fixing potential issues, and compiling on the first pass.
Full Application Development
From a one-sentence description of a "children's AI game training ground," LongCat-2.0 generates tech stack selection, page architecture, game logic, and visual details — producing three fully playable game pages in a single output, ready to run.
3D Interactive Demos
From a single natural language description, LongCat-2.0 generates complete Three.js 3D demos — transparent flasks, fluorescent liquid, foam eruptions, liquid level changes, and accumulation effects, all interactive in a single HTML file.
AI Novel Factory
An "AI Novel Factory" built on LongCat-2.0 orchestrates multiple agents for world-building, parallel chapter generation, quality evaluation, and revision loops — with million-token context ensuring consistency across novel-length settings. Content can be adapted for multi-platform publishing, with a web dashboard for real-time generation progress and quality monitoring.
Access & Resources
- Online experience: longcat.ai
- API (OpenRouter): openrouter.ai
- LongCat API platform: longcat.chat/platform/usage
- Model page: LongCat-2.0 Overview